
1.Python中的正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
1.1re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:
re.match(pattern, string, flags=0)
函数参数说明:
参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:https://www.runoob.com/python/python-reg-expressions.html#flags
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配成功re.match方法返回一个匹配的对象,否则返回None。
匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
以上实例运行输出结果为:
(0, 3) None
1.2re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
参数 描述 pattern 匹配的正则表达式 string 要匹配的字符串。 flags 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
实例 #!/usr/bin/python import re line = "Cats are smarter than dogs"; searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I) ##I忽略字符大小写,M垮多行匹配 if searchObj: print "searchObj.group() : ", searchObj.group() print "searchObj.group(1) : ", searchObj.group(1) print "searchObj.group(2) : ", searchObj.group(2) else: print "Nothing found!!"
以上实例执行结果如下:
searchObj.group() : Cats are smarter than dogs searchObj.group(1) : Cats searchObj.group(2) : smarter
1.3re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
实例
#!/usr/bin/python import re line = "Cats are smarter than dogs"; matchObj = re.match( r'dogs', line, re.M|re.I) if matchObj: print "match --> matchObj.group() : ", matchObj.group() else: print "No match!!" matchObj = re.search( r'dogs', line, re.M|re.I) if matchObj: print "search --> matchObj.group() : ", matchObj.group() else: print "No match!!"
以上实例运行结果如下:
No match!! search --> matchObj.group() : dogs
1.4检索和替换
Python 的 re 模块提供了re.sub用于替换字符串中的匹配项。
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
实例
#!/usr/bin/python # -*- coding: UTF-8 -*- import re phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r'#.*$', "", phone) print "电话号码是: ", num # 删除非数字(-)的字符串 num = re.sub(r'\D', "", phone) print "电话号码是 : ", num
以上实例执行结果如下:
电话号码是: 2004-959-559 电话号码是 : 2004959559
2.函数的基础概念
》函数是Python为了代码最大程度地重用和最小化代码冗余而提供的基本程序结构 》函数是一种设计工具,它能让程序员将复杂的系统分解为可管理的部件 》函数用于将相关功能打包并参数化 》在Python中可以创建4种函数 ——>全局函数:定义在模块中 -->局部函数:嵌套于其它函数中 -->lamdba函数:表达式 -->方法:与特定数据类型关联的函数,并且只能与数据类型关联一起使用 》Python提供了很多内置函数
2.1创建函数
>>语法
-->def functionname(paramètres)
#suite
>>一些相关的概念
-->def是一个可执行语句
#因此可以出现在任何能够使用语句的地方,甚至可以嵌套于其它语句,例如if或while中
-->def创建了一个对象并将其赋值给一个变量名(即函数名)
-->return用于返回结果对象,其为可选;无return语句的函数自动返回None对象
#返回多个指时,彼此间使用逗号分隔,且组合为元组形式返回一个对象
-->def语句运行之后,可以在程序中通过函数后附加括号进行调用
1.函数作用域
>>Python创建、改变或查找变量名都是在名称空间中进行 >>在代码中变量名被赋值的位置决定了其能被访问到的范围 >>函数定义了本地作用域,而模块定义了全局作用域 -->每个模块都是一个全局作用域,因此,全局作用域的范围仅限于单个程序文件 -->每次对函数的调用都会创建一个新的本地作用域,赋值的变量除非声明为全局变量,否则均为本地变量 -->所有的变量名都可以归纳为本地、全局或内置的(由__builtin__模块提供)
2.变量解析:LEGB原则
>>变量名引用分三个作用域进行:首先是本地、之后是函数内、接着是全局,最后是内置;

3.全局变量
>>全局变量是模块文件内部的顶层的变量名 >>如果要在函数内部对全局变量进行赋值的话,必须事先使用global进行声明 -->global关键字后跟一个或多个由逗号隔开的变量名 >>全局变量名在函数内部不经声明也可以被引用 >>本地变量在函数返回时会消失,而全局变量不会,因此。使用全局变量是保存函数状态信息的最直接办法 >>尽力避免使用全局变量
4.内嵌函数
>>Python中函数可以嵌套,也即可以在一个函数内部定义一个函数 >>在函数内部定义的函数仅能由外层函数进行调用 >>而如果外层函数直接把内层函数使用return返回,则调用外层函数时赋值的变量名引用的是一个内层函数对象,且此内层函数能够记忆其 内部引用的外层函数的变量,这种行为叫做工厂函数,也叫闭合函数 In [1]: def maker(N): ...: def action(X): ...: return X ** N ...: return action ...: In [2]: f = maker(2) In [5]: f(3) Out[5]: 9 In [6]: f(4) Out[6]: 16 In [7]: f = maker(3) In [8]: f(3) Out[8]: 27
5.参数传递
>>参数的传递是通过自动将对象赋值给本地变量实现的
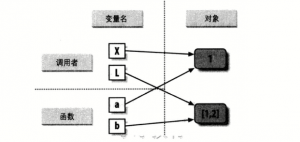
>>不可变参数通过"值"进行传递 -->在函数内部改变形参的值,只是让其引用了另一个对象 >>可变参数通过"指针"进行传递 -->在函数内部改变形参的值,将直接修改引用的对象
6.参数匹配模型
>>默认情况下,参数通过其位置进行传递;从左至右,这意味着,必须精确地传递和函数头部参数一样的参数 >>但也可以通过关键字参数、默认参数或参数容器等改变这种机制 -->位置:从左至右 -->关键字参数:使用"name=value"的语法通过参数名进行匹配 -->默认参数:定义函数时使用"name=value"的语法直接给变量一个值,从而传入的值可以少于参数个数 -->可变参数:定义函数时使用*开头的参数,可用于收集任意多基于位置或关键字的参数 -->可变参数解包:调用函数时,使用*开头的参数,可用于将参数集合打散,从而传递任意多基于位置或关键字的参数
7.匿名函数lambda
>>lambda运算符
-->lambda args:expression
@args:以逗号分隔的参数列表
@expression:用到args中各参数的表达式
-->lambda语句定义的代码必须是合法的表达式,不能出现多条件语句(可使用if的三元表达式)和其它非表达式语句,如
for和while等
-->lambda的首要用途是指定短小的回调函数
-->lambda将返回一个函数而不是将函数赋值给某变量名
>>注意
-->lambda是一个表达式而非语句
-->lambda是一个单个表达式,而不是一个代码块
>>def语句创建的函数将赋值给某变量名,而lambda表达式则直接返回函数
>>lambda也支持使用默认参数
def testfunc(x,y,z):
return x + y + z
testfunc(4,5,6)
15
f = lambda x,y,z: x+y+z
f(4,5,6)
15
f2 = (lambda x,y,z=10: x+y+z)
f2(4,5)
19
8.Python函数式编程
>>函数式编程 ->也称作泛函编程,是一种编程范型 ->它将电脑运算视为数学上的函数计算,并且避免状态以及可变数据 ->函数式编程语言最重要的基础是lambda演算,而且lambda演算的函数可以接受当中输入和输出 >>Python支持有限的函数式编程功能

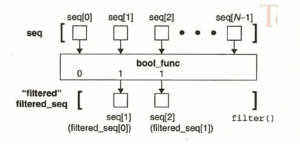
>>filte过滤器
->filter()为已知的序列的每个元素调用给定的布尔函数
->调用中,返回值为非零值得元素将被添加至一个列表中
def f1(x):
if x > 20:
return True
else:
return False
l1 = [1,2,3,45,64,16]
In [3]: filter(f1,l1)
Out[3]: [45, 64]
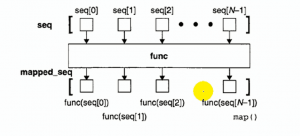
>>map()映射器 ->map()将函数调用"映射"到每个序列的对应元素上并返回一个含有所有返回值的列表 ->带有单个队列的map()如下图
9.函数装饰器,递归
函数中使用yield,会返回一个生成器对象 装饰器: 1.装饰器本身是一个函数 ,用于装饰其他函数 2.功能:增强被装饰函数的功能 装饰器一般接受一个函数对象作为参数, 使用@调用函数 递归: 在函数执行过程中调用自己 递归需要边界条件,递归前进段和递归返回段 In [1]: def fact(n): ...: if n <= 1:return 1 ...: else: return n * fact(n-1) In [2]: fact(3) Out[2]: 6 函数的设计规范 耦合性 1.通过参数接受输入,已经通过return产生输出以保证函数的独立性 2.尽量减少使用全局变量进行函数间通信 3.不要再函数中修改可变类型的参数 4.避免直接改变定义在另外一个模块中的变量 集合性 1.每个函数都应该有一个单一的、统一的目标 2.每个函数的功能都应该相对简单
3.Python类与面向对象
面向对象编程(OOP) >>程序 = 指令+数据 ->代码可以选择以指令为核心或以数据为核心进行编写 >>两种范型 ->以指令为核心:围绕"正在发生什么"进行编写 #面向过程编程:程序具有一系列线性步骤;主体思想是代码作用于数据 ->以数据为核心:围绕"将影响谁"进行编写 #面向对象编程(OOP):围绕数据及为数据严格定义的接口来组织程序,用数据控制对代码的访问
3.1面向对象的核心概念
>>所有编程语言的最终目的都是提供一种抽象方法
->在机器模型("解空间"或"方案空间")与实际解决问题模型("问题空间")之间,程序员必须建立一种联系
#面向过程:程序 = 算法+数据结构
#面向对象:将问题空间中的元素以及他们在解空间中的表示物抽象为对象,并允许通过问题来描述问题而不是方案
->可以把实例想象成一种新型变量,它保存着数据,但可以对自身的数据执行操作
>>类型由状态集合(数据)和转换这些状态的操作集合组成
->类抽象
#类:定义了被多个同一类型对象共享的结构和行为(数据和代码)
#类的数据和代码:即类的成员
@数据:成员变量或实例变量
@成员方法:简称为方法,是操作数据的代码,用于定义如何使用成员变量;因此一个类的行为和接口是通过方法来定义的
->方法和变量:
#私有:内部使用
#公共:外部可见
1.面向对象的程序设计方法
>>所有东西都是对象 >>程序是一大堆对象的组合 ->通过消息传递,各对象知道自己该做什么 ->消息:即调用请求,它调用的是从属于目标对象的一个方法 >>每个对象都有自己的存储空间,并可容纳其它对象 ->通过封装现有对象,可以制作成新型对象 >>每个对象都属于某一类型 ->类型,也即类 ->对象是类的实例 ->类的一个重要特性为"能发什么样的消息给它" >>同一个类的所有对象都能接收相同的消息
2.对象的接口
>>定义一个类后,可以根据需要实例化出多个对象 >>如何利用对象完成真正有用的工作? ->必须有一种办法能向对象发出请求,令其做一些事情 ->每个对象仅能接受特定的请求 #能向对象发送的请求由其"接口"进行定义 #对象的"类型"或"类"则规定了它的接口形式 类型名 Light 接口 on() off() brighten() dim()
3.类间关系
>>依赖("uses-a")
->一个类的方法操纵另一个类的对象
>>聚合("has-a")
->类A的对象包含类B的对象
>>继承("is-a")
->描述特殊与一般关系
4.面向对象编程的原则
>>面向对象的模型机制有3个原则:封装、继承及多态 >>封装(Encapsulation) ->隐藏实现方案细节 ->将代码及其处理的数据绑定在一起的一种编程机制,用于保证程序和数据不受外部干扰且不会被误用 >>继承(Inheritance) ->一个对象获得另一个对象属性的过程,用于实现按层分类的概念 ->一个深度继承的子类继承了类层次中它的每个祖先的所有属性 ->超类、基类、父类 ->子类、派生类 >>多态性(Polymorphism) ->允许一个接口被多个通用的类动作使用的特性,具体使用哪个动作与应用场合相关 ->"一个接口,多个方法" #用于为一组相关的动作设计一个通用的接口,以降低程序复杂性
3.2Python类和实例
>>类是一种数据结构,可用于创建实例 ->一般情况下,类封装了数据和可用于该数据的方法 >>Python类是一个可调用对象,即类对象 >>Python2.2之后,类是一种自定义类型,而实例则是声明某个自定义类型的变量 >>实例初始化 ->通过调用类来创建实例 #instance = ClassName(args...) ->类在实例化时可以使用__init__和__del__两个特殊的方法
1.Python中创建类
>>Python使用calss关键字创建类,语法格式如下 ->calss ClassName(bases): #'calss documentation string' #class suite ->超类是一个或多个用于继承的父类集合 ->类体可以包含:声明语句、类成员定义、数据属性、方法 ->注意 #如果不存在继承关系,ClassName后面的"(bases)"可以不提供 #类文档为可选 >>class语句的一般形式 ->class ClassName(bases): #data = value 定义数据属性 #def method(self,...): 定义方法属性 ->self.member = value 例子 >>Python中,class语句类似def,是可执行的代码;直到运行class语句后类才会存在




