
1.开始之前请思考如下问题
(1)Kubernetes的网络模型是什么
(2)Docker背后的网络基础是什么
(3)Docker自身的网络模型和局限是什么
(4)Kubernetes的网络组件之间是怎么通信的
(5)外部如何访问Kubernetes集群
(6)有那些开源组件支持Kubernetes的网络模型1.1 Kubernetes网络模型
kubernetes网络模型设计的一个基础原则是:每个Pod都拥有一个独立的IP地址,并假定所有Pod都在一个可以直接连通的、扁平的网络(接入、汇聚、核心三层网络架构进行了简化)空间中。所以不管它们是否运行在同一个node中,都要求它们可以直接通过对方的IP进行访问。设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑如何将容器端口映射到主机端口等问题。
实际上,在Kubernetes的世界里,IP是以Pod为单位进行分配的。一个Pod内部的所有容器共享一个网络堆(相当于一个网络命名空间,它们的IP地址、网络设置、配置等都是共享的)
为每个Pod都设置一个IP地址的模型还有另外一层含义,那就是同一个Pod内的不同容器会共享一个网络命名空间,也就是同一个Linux网络协议栈。这就意味着同一个Pod内的容器可以通过localhost来连接对方的端口。
IP-per-Pod模式(每个Pod都设置一个IP地址的模型)和Docker原生的通过动态端口映射方式实现的多节点访问模式有什么区别呢?主要区别是后者的动态端口映射会引入端口管理的复杂性,而且访问者看到的IP地址和端口与服务提供者实际绑定不同(因为NAT的缘故,它们都被映射成新的地址或端口了),这也会引起应用配置的复杂化。同时,标准的DNS等名字解析服务也不适用了,甚至服务注册和发现机制都将迎来挑战,因为在端口映射情况下,服务自身很难知道自己对外暴露的真实的服务IP和端口,外部应用也无法通过服务所在容器的私用IP地址和端口来反问服务。
总的来说,IP-per-Pod模型是一个简单的兼容性较好的模型。从改模型的网络的端口分配、域名解析、服务发现、负载均衡、应用配置和迁移等角度看,Pod都能够被看作一台独立的虚拟机或物理机。
按照这个网络抽象原则,Kubernetes对网络有什么前提和要求呢 Kubernetes对集群网络有如下要求
(1)所有容器都可以在不用NAT的方式下同别的容器通信
(2)所有节点都可以在不同NAT的方式下同所有容器通信,反之亦然
(3)容器的地址和别人看到的地址是同一个地址
这些基本要求意味着并不是只要两台机器都运行Docker,Kubernetes就可以工作了。具体的集群网络实现必须满足上述基本要求,原生的Docker网络目前还不能很好地支持这些要求。
实际上,这些对网络模型的要求并没有降低整个网络系统的复杂度。如果你的程序原来在VM上运行,而那些VM拥有独立的IP,并且它们之间可以直接透明地通信,那么Kubernetes的网络模型就和VM使用的网络模型一样。所以使用这种模型可以很容易地将已有的应用程序从VM或者物理机上迁移到容器。
Kubernete的网络依赖于Docker,Docker的网络又离不开Linux操作系统内核特性的支持,所以有必要先深入了解Docker背后的网络原理和基础知识 1.2Docker网络基础
Docker本身的技术依赖于Linux内核虚拟化技术,所以Docker对Linux的内核有很强的依赖性,这里将Docker使用到的与Linux网络有关的主要技术进行简要介绍,这些技术有:网络命名空间(Natework Namespace)、Veth设备对、网桥、iptables和路由1.2.1网络命名空间
为了支持网络协议栈的多个实例,Linux在网络栈中引入了网络命名空间,这些独立的协议栈被隔离到不同的命名空间中。处于不同命名空间中的网络栈是完全隔离的,彼此之间无法通信,就好像两个"平行宇宙"。通过对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。Docker正是利用了网络的命名空间特性,实现了不同容器之间的网络隔离。
在Linux的网络命名空间中可以有自己独立的路由表及独立的iptables设置来提供包转发、NAT及IP包过滤等功能
为了隔离出独立的协议栈,需要纳入命名空间的元素有进程、套接字、网络设备等。进程创建的套接字必须属于某个命名空间,套接字的操作也必须在命名空间中进行。同样,网络设置也必须属于命名空间。因为网络设置属于公共资源,所以可以通过修改属性实现在命名空间之间移动。当然,是否允许移动与设备的特征有关1.网络命名空间的实现
Linux的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的这些全局变量都必须被修改为协议栈私有。最好的办法就是让这些全局变量成为一个Net Namespace变量的成员,然后成为协议栈的函数调用加入一个Namespace参数。这就是Linux实现网络命名空间的核心。
在新建命名空间时,把某个进程关联到这个网络命名空间后,所有网站栈变量都被放入了网络命名空间的数据结构中。这个网络命名空间是其进程私有的,和其他进程组不冲突
在新生成的私有命名空间中只有回环设备(名为"lo"且是停止状态),其他设备默认都是不存在,如果我们需要,则要一一手工建立。Docker容器中的各类网络栈设备都是Docker Daemon在启动时自动创建和配置的
所有的网络设备(物理的或虚拟接口、桥等在内核里都叫作Net Device)都只能属于一个命名空间。当然,物理设备(连接实际硬件的设备)通常只能关联到root这个命名空间中。虚拟的网络设备(虚拟的以太网接口或者虚拟网口对)则可以被创建并关联到一个给定的命名空间中,而且可以在这些命名空间之间移动
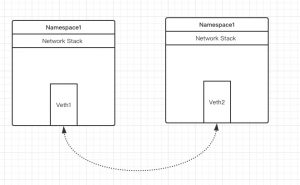
由于网络命名空间代表的是一个独立的协议栈,所以他们之间是相互隔离的,彼此无法通信,在协议栈内部看不到对方。那么有没有办法打破这种限制,让处于不同命名空间的网络相互通信,甚至和外部的网络进行通信呢?答案是"有,应用Veth设备对即可"。Veth设备对的一个重要作用就是打通互相看不到的协议栈之间的堡垒,它就像一条管子,一端连着这个网络命名空间的协议栈,一端连着另一个网络命名空间的协议栈。所以如果想在两个命名空间之间通信,就必须有一个Veth设备对。2.网络命名空间的操作
下面举例网络命名空间的一些操作
我们可以使用Linux iproute2系列配置工具中的IP命令来操作网络命名空间。注意,这个命令需要由root用户运行。创建一个命名空间:
[root@ds1 ~]# ip netns add kubns在命名空间中执行命令:
[root@ds1 ~]# ip netns exec kubns ls
## 也可以通过bash命令进入内部的shell界面,然后执行各种命令
[root@ds1 ~]# ip netns exec kubns bash
退出exit3.网络命名空间的实用技巧
操作网络命名空间时的一些实用技巧如下
我们可以在不同的网络命名空间之间转移设备,例如下面会提到的Veth设备对的转移。因为一个设备只能属于一个命名空间,所以转移后在这个命名空间中就看不到这个设备了。具体哪些设备被转移到不同的命名空间呢?在设备里面有一个重要的属性:
NETIF_F_ETNS_LOCAL,如果这个属性为on,就不能被转移到其他命名空间中。Veth设备属于可以转移的设备,而很多其他设备如lo设备、vxlan设备、ppp设备、bridge设备等都是不可以被转移的。将无法转移的设备移动懂别的命名空间时,会得到无效参数的错误提示。
[root@ds1 ~]# ip link set lo netns kubns
RTNETLINK answers: Invalid argument
如何知道这些设备是否可以转移呢?可以使用ethtool工具查看:
[root@ds1 ~]# ethtool -k lo |grep netns
netns-local: on [fixed]
1.2.2 Veth设备对
引入Veth设备对是为了在不同的网络命名空间之间通信,利用它可以直接将两个网络命名空间连接起来。由于要连接两个网络命名空间, 所以Veth设备都是成对出现的,很像一对以太网卡,并且中间有一根直连的网线。既然是一对网卡,那么我们将其中一端成为另一端的peer 在Veth设备的一端发送数据时,它会将数据直接发送到另一端,并触发另一端的接收操作。
这个Veth的实现非常简单,有兴趣的同学可以参考源代码"drivers/net/ceth.c"的实现
1.Veth设备对的操作命令
创建Veth设备对:
[root@ds1 ~]# ip link add veth0 type veth peer name veth1创建后,查看Veth设备对信息,使用ip link show命令查看所以网络接口:
[root@ds1 ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether fa:55:d3:0a:0a:00 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:a0:e1:ba:26 brd ff:ff:ff:ff:ff:ff
157: veth5a0deea@if156: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ba:fd:15:07:d2:eb brd ff:ff:ff:ff:ff:ff link-netnsid 0
158: veth1@veth0: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:ba:c4:0c:73:1b brd ff:ff:ff:ff:ff:ff
159: veth0@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 42:dd:4c:6c:84:78 brd ff:ff:ff:ff:ff:ff有两个设备生成了,一个是veth0,它的peer是veth1.
现在这两个设备都在自己的命名空间中,那怎么能行呢?好了,如果将Veth看作有两个头的网线,那么我们将另一个头甩给另一个命名空间:
[root@ds1 ~]# ip netns add netns1
[root@ds1 ~]# ip link set veth1 netns netns1这时可在外面这个命名空间中看两个设备的情况:
[root@ds1 ~]# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether fa:55:d3:0a:0a:00 brd ff:ff:ff:ff:ff:ff
3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:a0:e1:ba:26 brd ff:ff:ff:ff:ff:ff
157: veth5a0deea@if156: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether ba:fd:15:07:d2:eb brd ff:ff:ff:ff:ff:ff link-netnsid 0
159: veth0@if158: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 42:dd:4c:6c:84:78 brd ff:ff:ff:ff:ff:ff link-netnsid 1只剩一个veth0设备了,另一个设备已经被转移到另一个命名空间
#在netns1命名空间进行查看,符合预期
[root@ds1 ~]# ip netns exec netns1 ip link show
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
158: veth1@if159: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 8e:ba:c4:0c:73:1b brd ff:ff:ff:ff:ff:ff link-netnsid 0现在看到的结果是,两个不同的命名空间各自有一个Veth的”网线头”,各显示为一个Device(在Docker的实现里面,它除了将veth放入容器内,还将它的名字改成了eth0,简直以假乱真,你以为它是一个网卡吗)。
现在能通信了吗?不行,因为它们还没有任何地址,我们现在给它们分配IP地址:
[root@ds1 ~]# ip netns exec netns1 ip addr add 10.1.1.1/24 dev veth1
[root@ds1 ~]# ip addr add 10.1.1.2/24 dev veth0再启动它们:
[root@ds1 ~]# ip netns exec netns1 ip link set dev veth1 up
[root@ds1 ~]# ip link set dev veth0 up现在两个网络命名空间可以互相通信了:
[root@ds1 ~]# ping 10.1.1.1
PING 10.1.1.1 (10.1.1.1) 56(84) bytes of data.
64 bytes from 10.1.1.1: icmp_seq=1 ttl=64 time=0.059 ms
64 bytes from 10.1.1.1: icmp_seq=2 ttl=64 time=0.044 ms
64 bytes from 10.1.1.1: icmp_seq=3 ttl=64 time=0.057 ms
^C
--- 10.1.1.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1999ms
rtt min/avg/max/mdev = 0.044/0.053/0.059/0.008 ms
[root@ds1 ~]# ip netns exec netns1 ping 10.1.1.2
PING 10.1.1.2 (10.1.1.2) 56(84) bytes of data.
64 bytes from 10.1.1.2: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 10.1.1.2: icmp_seq=2 ttl=64 time=0.059 ms
64 bytes from 10.1.1.2: icmp_seq=3 ttl=64 time=0.045 ms
64 bytes from 10.1.1.2: icmp_seq=4 ttl=64 time=0.060 ms
^C
--- 10.1.1.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2999ms
rtt min/avg/max/mdev = 0.039/0.050/0.060/0.012 ms至此,我们就能够理解Veth设备对的原理和用法了。在Docker内部,Veth设备对也是连通容器与宿主机的主要网络设备,离开它是不行的。
2.Veth设备对如何查看对端
一旦将Veth设备对的对端放入另一个命名空间,在本命名空间中就看不到它了。那么我们怎么知道这个Veth设备的对端在哪里呢,可以使用ethtool工具来查看
首先,在命名空间netns1中查询Veth设备对端接口在设备列表中的序列号:
[root@ds1 ~]# ip netns exec netns1 ethtool -S veth1
NIC statistics:
peer_ifindex: 159得知另一端的接口设备的序列号是159,我们在本地命名空间中查看序列号为159代表的设备
[root@ds1 ~]# ip link|grep 159
159: veth0@if158: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
序列号159的设备是veth0,它的一端是netns1的veth1互为peer
如无特殊说明,文章均为本站原创,转载请注明出处
- 转载请注明来源:微服务网络原理
- 本文永久链接地址:https://www.xionghaier.cn/archives/1205.html

